
Volcano è un progetto della Cloud Native Computing Foundation (CNCF) che viene utilizzato principalmente come sistema batch nel campo dell'AI e per applicazioni Big Data quando l'ambiente è costruito su Kubernetes.
Il progetto Volcano della CNCF è un sistema batch costruito su Kubernetes. Il focus dei carichi di lavoro è principalmente carichi di lavoro dal campo dell'AI (machine learning/deep learning) e altre applicazioni Big Data che causano un alto carico computazionale e devono essere programmati in modo ottimale nel cluster Kubernetes.
Frameworks come "Tensorflow", "Spark", "Pytorch", "MPI", "Flink", "Argo", "Mindspore" e "PaddlePaddle" che richiedono carichi di lavoro elevati lavorano bene con Volcano. Volcano supporta l'integrazione con vari framework di calcolo, per esempio "Kubeflow" e "Kubegene".
Volcano estende Kubernetes con varie funzioni. Questi includono principalmente estensioni di scheduling, estensioni di gestione del lavoro e acceleratori come GPU e FPGA.
Schedulazione raggruppata per contenitori
Volcano è uno dei progetti emersi da "Kube Batch". Il progetto è stato originariamente creato per raggruppare meglio i contenitori e programmare le risorse.
Soprattutto per le soluzioni AI e Big Data, Volcano nei cluster Kubernetes è un componente importante per un migliore utilizzo delle risorse. Con Volcano, è possibile accelerare significativamente i carichi di lavoro AI in cluster Kubernetes.
Originariamente accettato dal CNCF nel 2015 come progetto sandboxed 'Kubernetes-native system for high-performance workloads', ha ottenuto la denominazione Volcano nel 2019. Il codice sorgente del progetto e i problemi possono essere trovati anche su Github.
Addizione per lo scheduler di Kubernetes
Lo scheduler in Kubernetes programma i container uno alla volta. Questo è utile per molti scenari, ma raramente per i carichi di lavoro con compiti ad alta intensità di calcolo. Specialmente quando si addestrano gli ambienti AI e anche nelle analisi dei Big Data, interi gruppi di container giocano spesso un ruolo importante.
Se un'applicazione ha bisogno di diversi contenitori per la sua esecuzione, può succedere con lo scheduler standard di Kubernetes, causato da una schedulazione singola, che i singoli contenitori del gruppo non possano partire perché non ci sono abbastanza risorse disponibili. Di conseguenza, tali carichi di lavoro vengono eseguiti meno efficacemente o non vengono eseguiti affatto.
Al tempo stesso, però, i contenitori del gruppo che sono già stati avviati causano risorse che non servono a niente, perché manca un componente essenziale del gruppo. Questo è l'approccio di Volcano. La soluzione combina l'intero gruppo di container interdipendenti e programma le loro risorse insieme.
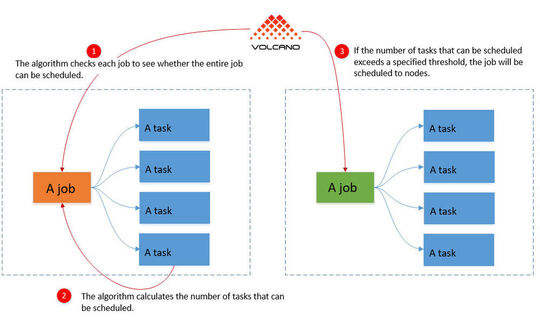
Se tutti i container nel gruppo non possono partire, Volcano impedisce a tutti i container del gruppo di partire. Questo riduce significativamente il carico sul cluster Kubernetes, poiché in questo caso almeno le risorse sono disponibili per altri container e gruppi di container. Se diversi gruppi di questo tipo sono in esecuzione in un cluster, l'uso di Volcano ha perfettamente senso.
Allocazione automatica delle risorse per i contenitori
Volcano ha una visione completa dei singoli contenitori su Kubernetes attraverso le sue funzioni interne, ma anche di gruppi di contenitori che forniscono congiuntamente un carico di lavoro. Oltre a raggruppare e condividere le risorse tra i contenitori, il software può anche identificare quali nodi sono più adatti a fornire i singoli contenitori in un gruppo.
La CPU, la memoria, la GPU e altre risorse possono anche essere specificamente programmate e messe a disposizione dei contenitori di un gruppo. Volcano conosce le risorse libere e il carico massimo di tutti i nodi. Sulla base di queste informazioni, Volcano seleziona il nodo più adatto per ogni contenitore.
Volcano offre anche la possibilità di lavorare con priorità. Funzioni come Domain Resource Fairness (DRF) e Binpack sono anche integrate in Volcano e possono essere prese in considerazione nella pianificazione delle risorse. Se diversi gruppi sono in competizione tra loro o non dovrebbero essere usati insieme su un nodo, questo può essere preso in considerazione con Volcano.
Come funziona Volcano
Domain Resource Fairness (DRF) può dare priorità ai lavori, anche in YARN e Mesos. Per esempio, DRF può anche dare la priorità ai lavori che richiedono meno risorse. Questo fa sì che il cluster sia in grado di eseguire più lavori e che i piccoli compiti non vengano bloccati da applicazioni di grandi dimensioni. In Volcano, DRF definisce un lavoro come l'insieme di tutti i contenitori necessari per un compito definito.
L'algoritmo binpack cerca di utilizzare tutti i nodi del cluster il più possibile. Le configurazioni possono essere fatte in modo che i nodi siano prima completamente occupati prima che Vulcano occupi altri nodi. Binpack pianifica l'utilizzo di tutti i nodi nel cluster e poi programma i singoli lavori in base a queste specifiche.
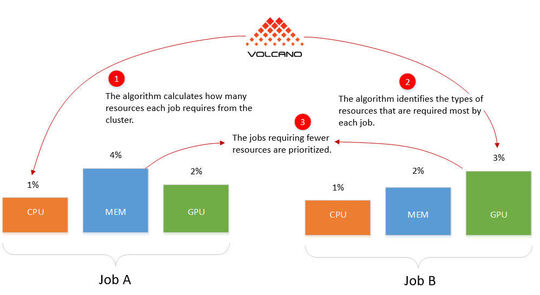
L'algoritmo di accodamento può controllare l'intera assegnazione delle risorse di un cluster. Questa tecnica è utilizzata anche in YARN. Se diversi gruppi di container condividono un pool di risorse in un cluster, Volcano può controllare quale gruppo ha bisogno di più risorse.
In questo modo, Volcano riconosce anche in un tale scenario quale gruppo utilizza probabilmente meno risorse e può eseguire questo gruppo per primo. Una volta che i loro compiti sono completati, Volcano può pianificare il gruppo con il carico di risorse più alto. Volcano può pesare i suoi diversi plug-in di algoritmi di pianificazione in modo diverso.
Ergo: Se i carichi di lavoro sono utilizzati su un cluster Kubernetes che sono basati su diversi container e pod e hanno un alto consumo di risorse, Volcano può portare vantaggi significativi. Il suo uso è particolarmente utile quando si lavora con carichi di lavoro AI, per esempio per l'apprendimento automatico e l'apprendimento profondo. Ma anche altri carichi di lavoro affamati di risorse nell'area dei Big Data per il rendering e i calcoli completi beneficiano di Volcano.
Finalmente, Volcano porta anche alcuni vantaggi per gli altri carichi di lavoro nel cluster, perché la pianificazione delle risorse molto migliore significa che gli altri carichi di lavoro possono anche utilizzare più risorse, o hanno la priorità all'avvio perché hanno bisogno di meno risorse e quindi finiscono il loro lavoro più rapidamente.
* L'autore Thomas Joos è un consulente IT e scrive libri e articoli tecnici. Su DataCenter-Insider riempie il suo blog con consigli e trucchi per gli amministratori. "Tom's Admin Blog".